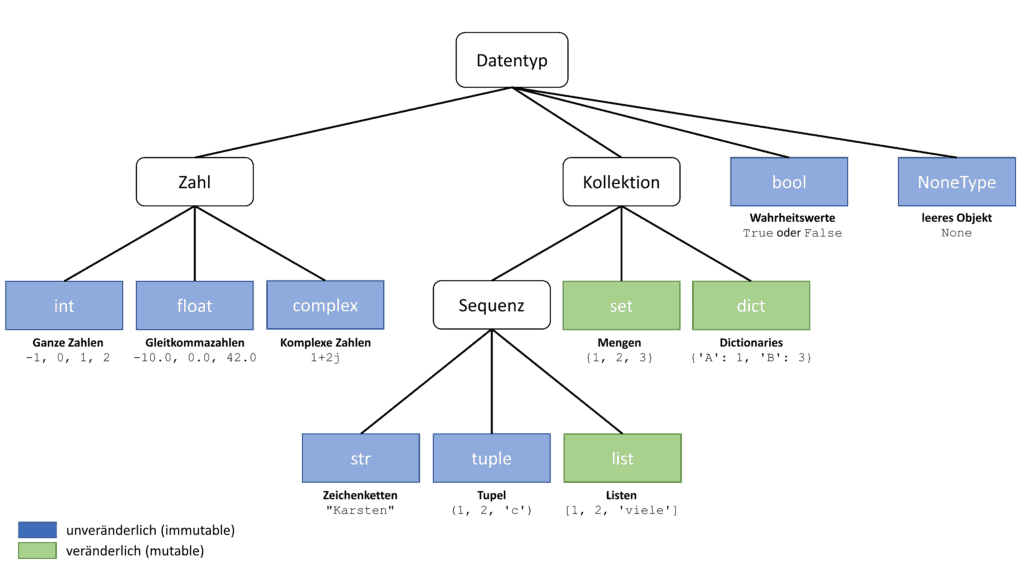
Datentyp-Hierarchie (Wiederholung)
Zu Deiner besseren Orientierung zeige ich hier nochmals die Datentyp-Hierarchie von Python. Die Zahlendatentypen, Wahrheitswerte, Listen und Tupel haben wir den vorangegangenen Abschnitten behandelt. Jetzt widmen wir uns den Zeichenketten.
Zeichen und Zeichenketten
Informatiker bezeichnen eine Zeichenkette gerne als String. In Python heißt der Datentyp str. Python unterscheidet nicht zwischen einzelnen Zeichen und Zeichenketten. Ein Zeichen ist in Python eine Zeichenkette, die aus nur einem Zeichen besteht. Zeichenkettenliterale werden paarweise in einfache oder doppelte Anführungszeichen eingeschlossen. Bei der Darstellung von Zeichenketten verwendet der interaktive Python-Modus üblicherweise die Notation mit einfachen Anführungszeichen.
>>> 'Hallo Python'
'Hallo Python'
>>> "Hallo Python"
'Hallo Python'
Ich selbst habe mir die Konvention auferlegt, Zeichenkettenliterale in doppelten Anführungszeichen zu schreiben. Einfache Anführungszeichen verwende ich, um optisch erkennbar zu machen, dass ich an dieser Stelle tatsächlich nur mit einzelnen Zeichen arbeiten möchte.
Eine Art von Anführungszeichen schützt die andere. Innerhalb von doppelten Anführungszeichen können einfache Anführungszeichen wie normale andere Zeichen gehandhabt werden und umgekehrt.
>>> 'Er sagte: "Hallo Python"'
'Er sagte: "Hallo Python"'
>>> "Er sagte: 'Hallo Python'"
"Er sagte: 'Hallo Python'"
Im zweiten Fall verwendet auch die Python-Shell die doppelten Anführungszeichen, um im Innern der Zeichenkette die einfachen Anführungszeichen darstellen zu können.
Möchtest Du Zeichenketten notieren, die auch Zeilenumbrüche enthalten sollen, so hast Du zwei Möglichkeiten.
Die erste Möglichkeit ist die, sogenannte lange Zeichenketten zu verwenden. Sie werden paarweise in drei einfache oder doppelte Anführungszeichen eingeschlossen.
>>> """Lange Zeichenkette,
... mit Zeilenumbruch"""
'Lange Zeichenkette,\nmit Zeilenumbruch'
Die Ausgabe entspricht sicher nicht dem, was Du erwartet hast. Sie gibt aber Aufschluss über die alternative Notation. Die Zeichenfolge \n ist eine sogenannte Escape-Sequenz. Der Backslash entwertet das direkt folgende Zeichen und gibt ihm eine Sonderbedeutung. \n steht für einen Zeilenumbruch (Line Feed). Wir hätten also mithilfe einer kurzen Zeichenkette das Folgende schreiben können.
>>> "Lange Zeichenkette,\nmit Zeilenumbruch"
'Lange Zeichenkette,\nmit Zeilenumbruch'
Das Ergebnis entspricht der vorigen Ausgabe.
Um eine Zeichenkette oder andere Dinge schöner ausgeben zu können, so wie wir das üblicherweise erwarten, gibt es die print()-Funktion. Sie setzt
>>> print("Lange Zeichenkette\nmit Zeilenumbruch")
Lange Zeichenkette
mit Zeilenumbruch
Neben \n gibt es weitere Zeichen, die in der Regel nicht direkt über die Tastatur eingebbar sind und deshalb literal als Escape-Sequenzen notiert werden können. Folgende Escape-Sequenzen werden von Python unterstützt:
| Escape-Sequenz | Beschreibung |
|---|---|
\' |
einfacher Anführungsstrich |
\" |
doppelter Anführungsstrich |
\\ |
Backslash |
\n |
Line Feed |
\r |
Carriage Return |
\t |
horizontaler Tabulator |
\b |
Backspace |
\f |
Form Feed |
\ooo |
Oktalcode eines Zeichens |
\xhh |
Hexadezimalcode eines Zeichens |
Zeichen können auch durch Angabe ihrer Kodierung, oktal oder hexadezimal, angegeben werden. Bei Zeichen, die über die Tastatur erreichbar sind, macht dies selten Sinn. Bei Sonderzeichen ist dies allerdings nützlich, wie das folgende Beispiel zeigt.
>>> '\xA5'
'¥'
Wenn Du Dir die numerischen Zeichencodes anzeigen lassen möchtest, so kannst Du dazu die ord()-Funktion verwenden. Ihr übergibst Du ein einzelnes Zeichen und erhältst dann den dezimalen Zeichencode. Umgekehrt wirkt die Funktion chr(). Ihr übergibst Du eine dezimale Ganzzahl, den Zeichencode, und erhältst das entsprechende Zeichen.
>>> ord('文')
25991
>>> chr(25991)
'文'
Hinweis: Unter macOS und Gnu/Linux werden diese Sonderzeichen in der Regel auch im Terminal angezeigt. Bei Microsoft Windows musst Du IDLE als Python-Shell verwenden, um die Beispiele nachzuvollziehen. Unter Windows fehlen den Schriften im Terminal die erforderlichen Glyphen, die Zeichen darzustellen.
Operationen auf Zeichenketten
Der +-Operator ist für Zeichenketten überladen. Zeichenketten lassen sich damit zusammenfügen.
>>> vorname = "Karsten"
>>> nachname = "Brodmann"
>>> name = nachname + ", " + vorname
>>> name
'Brodmann, Karsten'
Neben dem +-Operator ist auch der *-Operator für Zeichenketten überladen. Mit ihm kannst Du Zeichenketten wiederholen.
>>> "Bla"*3
'BlaBlaBla'
Auf die einzelnen Zeichen oder Zeichengruppen einer Zeichenkette wird über einen Index zugegriffen, der analog zu den Listen funktioniert. Du kannst die Elemente einer Zeichenkette jedoch nicht verändern. Zeichenketten sind immutable (unveränderlich).
>>> vorname = "Karsten"
>>> id(vorname)
2326559557488
>>> vorname[0] = 'C' # FEHLER
Traceback (most recent call last):
File "<pyshell#79>", line 1, in <module>
vorname[0] = 'C' # FEHLER
TypeError: 'str' object does not support item assignment
>>> vorname = 'C' + vorname[1:] # neue Zeichenkette
>>> vorname
'Carsten'
>>> id(vorname)
2326553406000
Du siehst, die IDs der Variablen vorname haben sich geändert! Die Variable zeigt also auf ein neues Zeichenkettenobjekt.
Zeichenketten sind in Python sehr mächtig, besitzen eine Menge Features.
Trennen von Zeichenketten
| Methode | Beschreibung |
|---|---|
s.split([sep[, maxsplit]]) |
s bei sep trennen; optional maximale Anzahl der Trennungen (Standard: alle); Ergebnis: Liste der Textteile/td>
|
s.rsplit([sep[, maxsplit]]) |
dto. von hinten beginnend |
s.splitlines([keepends]) |
s bei Zeilentrennen teilen |
s.partition(sep) |
s bei Vorkommen von sep teilen (Ergebnis: Tupel (teil1 ,sep, Teil2) |
s.rpartition(sep) |
dto. von hinten |
Der Parameter maxsplit gibt eine Anzahl an, keepends gibt an, ob die Zeilenenden erhalten bleiben sollen.
Beispiele zu partition() und rpartition():
>>> domain = "www.punkt-akademie.de"
>>> domain.partition('.')
('www', '.', 'punkt-akademie.de')
>>> domain.rpartition('.')
('www.punkt-akademie', '.', 'de')
Beispiele zu splitlines():
>>> text = "erste Zeile\nzweite Zeile\ndritte Zeile"
>>> text.splitlines()
['erste Zeile', 'zweite Zeile', 'dritte Zeile']
>>> text.splitlines(True)
['erste Zeile\n', 'zweite Zeile\n', 'dritte Zeile']
Beispiele zu split():
>>> text = " Ein Text \n\t mit \r\nWhitspaces "
>>> text.split()
['Ein', 'Text', 'mit', 'Whitspaces']
Ohne Angabe eines Trennmusters werden alle Whitespaces einer Zeichenkette entfernt und diese an den entsprechenden Stellen zerteilt.
Anders sieht das aus, wenn ein konkretes Trennmuster angegeben wird.
>>> text = "1-2---3--4"
>>> text.split('-')
['1', '2', '', '', '3', '', '4']
>>> text.split('--')
['1-2', '-3', '4']
Suchen in Zeichenketten
| Methode | Beschreibung |
|---|---|
s.find(sub[, start [, end]]) |
sub in s suchen; optional von start bis end |
s.rfind(sub[, start [, end]]) |
dto. von hinten beginnend |
s.index(sub[, start [, end]]) |
Position von sub in s; optional Bereich angeben |
s.rindex(sub[, start [, end]]) |
dto. von rechts beginnend |
s.count(sub[, start [, end]]) |
Anzahl des Vorkommens von sub in s; optional Bereich angeben |
>>> text = "Das Weinfass, das Frau Weber leerte, "
>>> text += "verheerte ihre Leberwerte."
>>> text.count('e')
15
>>> text.find("Das")
0
>>> text.find("Frau")
18
>>> text.find("Frau", 18)
18
>>> text.find("Frau", 20)
-1
>>> text.index("Frau", 18)
18
>>> text.index("Frau", 20) # Fehler!
Traceback (most recent call last):
File "<pyshell#22>", line 1, in <module>
text.index("Frau", 20) # Fehler!
ValueError: substring not found
find() und index() unterscheiden sich in Bezug auf ihr Verhalten, wenn das gesuchte Muster nicht gefunden wird.
Ersetzen innerhalb von Zeichenketten
| Methode | Beschreibung |
|---|---|
s.replace(old, new [, count]) |
old durch new ersetzen |
s.lower() |
alles in Kleinbuchstaben |
s.upper() |
alles in Großbuchstaben |
s.swapcase() |
Groß-/Kleinschreibung vertauschen |
s.capitalize() |
|
s.casefold() |
ähnlich \verb|lower()|, ß wird zu ss |
s.title() |
erster Buchstabe jeden Wortes groß, Rest klein |
s.expandtabs([tabsize]) |
Tabulatoren durch entsprechende Anzahl Leerzeichen ersetzen, die tabsize erfordert (Standard: 8) |
>>> name = "KARSTEN brodmann"
>>> name.capitalize() # ACHTUNG: 2. Wort bleibt
'Karsten brodmann'
>>> name.title() # besser?
'Karsten Brodmann'
Entfernen von Zeichen an Anfang und Ende einer Zeichenkette
| Methode | Beschreibung |
|---|---|
s.strip([chars]) |
Zeichen an Anfang und Ende entfernen |
s.lstrip([chars]) |
Zeichen an Anfang entfernen |
s.rstrip([chars]) |
Zeichen am Ende entfernen |
Ohne konkretes Muster, welches entfernt werden soll, eliminieren alle strip()-Varianten alle Whitespaces.
>>> text = " \t\n Ein Text \n "
>>> text.strip()
'Ein Text'
Das folgende Muster extrahiert den Text aus allen Markdown-Überschriften, egal welchen Grades sie sind.
>>> markdownheader = "## Überschrift 2. Grades"
>>> markdownheader.lstrip("# ")
'Überschrift 2. Grades'
Ausrichten von Zeichenketten
Im Folgenden ist fillchar genau ein optionales Zeichen, welches zum Auffüllen verwendet wird. Der Vorgabewert ist ein Leerzeichen.
| Methode | Beschreibung |
|---|---|
s.center(width [,fillchar]) |
zentrierte Ausgabe |
s.ljust(width [,fillchar]) |
linksbündige Ausgabe |
s.rjust(width [,fillchar]) |
rechtsbündige Ausgabe |
s.zfill(width) |
dto., links mit Nullen aufgefüllt |
>>> text = "Ausgabe"
>>> text.center(30, '-')
'-----------Ausgabe------------'
>>> text.rjust(30, '-')
'-----------------------Ausgabe'
>>> text.ljust(30, '-')
'Ausgabe-----------------------'
Zeichenketten auf bestimmte Eigenschaften testen
| Methode | Beschreibung |
|---|---|
s.isalnum() |
Buchstaben und/oder Ziffern? |
s.isalpha() |
alle Zeichen Buchstaben? |
s.isdigit() |
alle Zeichen Ziffern? |
s.islower() |
alle Buchstaben klein? |
s.isupper() |
alle Buchstaben groß? |
s.isspace() |
nur Whitespaces? |
s.istitle() |
jeder 1. Buchstabe eines Wortes groß, Rest klein? |
s.startswith(pattern [, start, end]) |
(Bereich) beginnt mit \verb|pattern| |
s.endswith(pattern [, start, end]) |
(Berecih) endet mit \verb|pattern|? |
Beispiele:
>>> domain = "www.punkt-akademie.de"
>>> domain.startswith("www")
True
>>> domain.endswith(".com")
False
>>> domain.startswith("punkt", 4)
True
Elemente sequentieller Datentypen zu Zeichenketten verknüpfen
Zeichenketten mittels der überladenen Operatoren + und * verknüpfen zu können, kennst Du bereits. Oftmals möchtest Du eine Zeichenkette aber aus den Zeichenketten-Elementen (!) eines sequentiellen Datentyps zusammensetzen, zum Beispiel eine Zeichenkette als kommaseparierte Aufzählung aller Elemente einer Liste erstellen. Dafür gibt es die Methode join().
Die Syntax lautet:
sep.join(seq)
sep ist das Trennmuster, welches zwischen den Elementen von seq eingefügt wird.
>>> seq = ("1", "2", "3", "4")
>>> sep = " - "
>>> sep.join(seq)
'1 - 2 - 3 - 4'
Etwas trickreich ist es, zum Beispiel eine Sequenz ganzer Zahlen als Zeichenkette mit Trennzeichen auszugeben. Dazu erinnern wir uns an die List Comprehension. Das dort gezeigte Prinzip gilt nicht nur für Listen. Comprehensions können vielseitig eingesetzt werden.
>>> seq = (1, 2, 3, 4, 5, 6)
>>> sep = ", "
>>> sep.join(str(i) for i in seq)
'1, 2, 3, 4, 5, 6'
Formatierung
Die schönsten Berechnungen nutzen wenig, wenn wir die Resultate nicht adäquat ausgeben können. So wollen wir wohlgestaltete Tabellen ausgeben, Daten in Spalten ausrichten und andere Dinge mehr.
Seit der Python-Version 3.0 gibt es dafür die Methode format(). Sie ist vielseitig und einfach zu verwenden. Zudem gibt es seit geraumer Zeit auch die sogenannten F-Strings. Das ist eine noch neuere und ebenfalls sehr flexibel und einfach zu verwendende Art und Weise, um Daten formatiert auszugeben. – Ich verwende hier die format()-Methode. Sie hat den Vorteil auch mit nicht ganz aktuellen Python-Versionen zu funktionieren. Es obliegt aber dem Leser, sich auch die F-Strings anzusehen und diese vielleicht bevorzugt zu verwenden.
Die format()-Methode ist eine Methode, die jede Zeichenketteninstanz besitzt. Mit ihrer Hilfe kannst Du in einer Zeichenkette Platzhalter durch bestimmte Werte ersetzen lassen. Diese Platzhalter werden durch geschweifte Klammern dargestellt und können beliebige Objekte repräsentieren, die eine Zeichenkettendarstellung besitzen. Es gibt verschiedene Notationen für die Platzhalter. Sie können anonym eingefügt werden, positionelle Bezüge zu den Argumenten von format() besitzen oder gar mit Bezeichnern versehen werden. – Wir werden uns die Spielarten im Folgenden ansehen.
>>> meldung = "Beim nächsten Ton ist es: {} Uhr, {} Minuten und {} Sekunden".format(18, 4, 25)
>>> print(meldung)
Beim nächsten Ton ist es: 18 Uhr, 4 Minuten und 25 Sekunden
Grundsätzlich gilt: Möchtest Du verhindern, dass geschweifte Klammern als Platzhalter interpretiert werden, dann schreibe sie doppelt.
>>> meldung = "{{Kein Platzhalter}} dies ist ein {{{}}}"
>>> meldung = meldung.format("Platzhalter")
>>> print(meldung)
{Kein Platzhalter} dies ist ein {Platzhalter}
Der Formalismus ist jetzt klar. Viel gewonnen haben wir aber noch nicht. Das Bisherige hätten wir auch mit bloßer Zeichenkettenverknüpfung erreichen können. Richtig schön wird eine Ausgabe erst dann formatiert, wenn wir uns einer Formatangabe bedienen. Bevor wir sie uns im Detail ansehen, möchte ich kurz den prinzipiellen Aufbau darstellen:
:[[fill]align][sign][#][0][minimumwidth][,][.precision][type]
Minimale Ausgabebreite (minimumwidth)
Gibst Du als Formatangabe einfach eine ganze Zahl nach dem Doppelpunkt an, steht diese für die Mindestanzahl von Zeichen, die die Ausgabe des Platzhalterwertes einnehmen soll. Auf diese Weise kannst Du beispielweise die Breite einer Tabellenspalte festlegen.
>>> f = "{:15} | {:15} |"
>>> print(f.format("Brodmann", "Karsten"))
Brodmann | Karsten |
>>> print(f.format("Hauser", "Julian"))
Hauser | Julian |
Sollte ein Wert länger sein als die minimale Breite, wird die Ausgabebreite der tatsächlich erforderlichen Anzahl an Zeichen angepasst. Es wird nichts abgeschnitten.
Ausrichtung (align)
Die Standardausrichtung ist linksbündig (<) und braucht nicht angegeben zu werden. Wünschst Du eine rechtsbündige Ausgabe, so kennzeichnest Du diese mit >. = sorgt bei numerischen Werten ebenso für eine rechtsbündige Ausgabe. Dabei werden aber die Vorzeichen am linken Rand des Ausgabefeldes ausgegeben. ^ zentriert die Ausgabe.
>>> f = "| {txt:9} | {txt:>9} | {txt:^9} |"
>>> print(f.format(txt="xxx"))
| xxx | xxx | xxx |
Ein --Zeichen sorgt dafür, bei negativen Zahlen ein Minuszeichen voranzustellen (Standardverhalten). Das musst Du also nicht extra angeben. Ein +-Zeichen sorgt dafür, dass das Vorzeichen einer Zahl immer mit ausgegeben wird. Ein Leerzeichen fügt bei positiven Zahlen eine Leerstelle ein, negative Vorzeichen werden ausgegeben.
>>> f = "{n1:-}\n{n1:+}\n{n1: }\n{n2:-}\n{n2:+}\n{n2: }"
>>> print(f.format(n1=42, n2=-42))
42
+42
42
-42
-42
-42
Zahlendarstellungen ganzer Zahlen
| Methode | Beschreibung |
|---|---|
b |
Binärdarstellung |
c |
Unicode-Zeichen |
d |
Dezimaldarstellung |
o |
Oktaldarstellung |
x |
Hexadezimaldarstellung mit Kleinbuchstaben |
X |
Hexadezimaldarstellung mit Großbuchstaben |
n |
wie d, jedoch regionale Zahlendarstellung |
Die ganzen Zahlen können in dezimaler Schreibweise (Standard) ausgegeben oder in andere Zahlensysteme oder gar Unicode-Zeichen umgerechnet/konvertiert werden.
Hinweis: Für nationale Darstellungen müssen die entsprechenden Lokaleinstellunngen geladen sein!
>>> import locale # erforderlich für regionale Formatierung
>>> locale.setlocale(locale.LC_ALL, "")
'German_Germany.1252'
>>> f = "{n:d}\n{n:b}\n{n:o}\n{n:x}\n{n:X}\n{n:n}"
>>> print(f.format(n=123456))
123456
11110001001000000
361100
1e240
1E240
123.456
>>> f="{:c}"
>>> print(f.format(25991))
文
Hinweis: Microsoft Windows ist bezüglich der Darstellung besonderer Schriftzeichen sehr schwach. Bei macOS und Gnu/Linux kann man aber sehr schicke Schriftzeichen anzeigen. Das Zeichen 文 ist im Windows-Terminal nicht darstellbar. Es fehlen die notwendigen Glyphen.
In Deutschland unüblich, aber möglich, sind zwei alternative Tausendertrennzeichen: das Komma oder der Unterstrich.
>>> print("{:,d}".format(123456))
123,456
>>> print("{:_d}".format(123456))
123_456
Darstellung von Gleitkommazahlen
Gleitkommazahlen sind nur zur Basis 10 darstellbar. Für die nationale Darstellung sind die Lokaleinstellungen zu setzen (siehe oben).| Format | Beschreibung |
|---|---|
e |
wissenschaftliche Schreibweise mit e |
E |
wissenschaftliche Schreibweise mit E |
f |
Ausgabe mit Dezimalpunkt |
g |
wie f, bei langen Zhalen wie e |
G |
wie f, bei langen Zhalen wie E |
n |
nationales Format |
% |
Prozentwert |
wie g, mindestens eine Nachkommastelle |
>>> f = "{n:e}\n{n:E}\n{n:f}\n{n:g}\n{n:G}\n{n:n}\n{n}\n{p:%}"
>>> print(f.format(n=1234567890.12345678, p=0.42))
1.234568e+09
1.234568E+09
1234567890.123457
1.23457e+09
1.23457E+09
1,23457e+09
1234567890.1234567
42.000000%
Rundung/Präzision der Ausgabe von Gleitkommazahlen
Nicht immer will man alle Nachkommastellen ausgeben. Die Angabe vonprecision schneidet jedoch nicht einfach überschüssige Stellen ab, es wird gerundet.
>>> f = "{n:.2e}\n{n:.2E}\n{n:.2f}\n{n:.2g}\n"
>>> f += "{n:.2G}\n{n:.2n}\n{p:.2%}"
>>> print(f.format(n=1234567890.12345678, p=0.42))
1.23e+09
1.23E+09
1234567890.12
1.2e+09
1.2E+09
1,2e+09
42.00%